







It's been a while since I've done a benchmark of different compilers on C++ code. Since I've recently released the version 1.1 of my ETL project (an optimized matrix/vector computation library with expression templates), I've decided to use it as the base of my benchmark. It's a C++14 library with a lot of templates. I'm going to compile the full test suite (124 test cases). This is done directly on the last release (1.1) code. I'm going to compile once in debug mode and once in release_debug (release plus debug symbols and assertions) and record the times for each compiler. The tests were compiled with support for every option in ETL to account to maximal compilation time. Each compilation was made using four threads (make -j4). I'm also going to test a few of the benchmarks to see the difference in runtime performance between the code generated by each compiler. The benchmark will be compiled in release mode and its compilation time recorded as well.
I'm going to test the following compilers:
- GCC-4.9.4
- GCC-5.4.0
- GCC-6.3.0
- GCC-7.1.0
- clang-3.9.1
- clang-4.0.1
- zapcc-1.0 (commercial, based on clang-5.0 trunk)
All have been installed directly using Portage (Gentoo package manager) except for clang-4.0.1 that has been installed from sources and zapcc since it does not have a Gentoo package. Since clang package on Gentoo does not support multislotting, I had to install one version from source and the other from the package manager. This is also the reason I'm testing fewer versions of clang, simply less practical.
For the purpose of these tests, the exact same options have been used throughout all the compilers. Normally, I use different options for clang than for GCC (mainly more aggressive vectorization options on clang). This may not lead to the best performance for each compiler, but allows for comparison between the results with defaults optimization level. Here are the main options used:
- In debug mode: -g
- In release_debug mode: -g -O2
- In release mode: -g -O3 -DNDEBUG -fomit-frame-pointer
In each case, a lot of warnings are enabled and the ETL options are the same.
All the results have been gathered on a Gentoo machine running on Intel Core i7-2600 (Sandy Bridge...) @3.4GHz with 4 cores and 8 threads, 12Go of RAM and a SSD. I do my best to isolate as much as possible the benchmark from perturbations and that my benchmark code is quite sound, it may well be that some results are not totally accurate. Moreover, some of the benchmarks are using multithreading, which may add some noise and unpredictability. When I was not sure about the results, I ran the benchmarks several times to confirm them and overall I'm confident of the results.
Compilation Time
Let's start with the results of the performance of the compilers themselves:
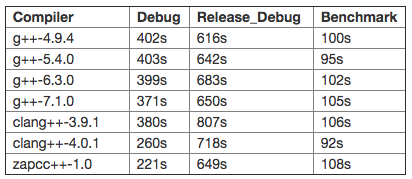
Note: For Release_Debug and Benchmark, I only use three threads with zapcc, because 12Go of RAM is not enough memory for four threads.
There are some very significant differences between the different compilers. Overall, clang-4.0.1 is by far the fastest free compiler for Debug mode. When the tests are compiled with optimizations, however, clang is falling behind. It's quite impressive how clang-4.0.1 manages to be so much faster than clang-3.9.1 both in debug mode and release mode. Really great work by the clang team here! With these optimizations, clang-4.0.1 is almost on par with gcc-7.1 in release mode. For GCC, it seems that the cost of optimization has been going up quite significantly. However, GCC 7.1 seems to have made optimization faster and standard compilation much faster as well. If we take into account zapcc, it's the fastest compiler on debug mode, but it's slower than several gcc versions on release mode.
Overall, I'm quite impressed by the performance of clang-4.0.1 which seems really fast! I'll definitely make more tests with this new version of the compiler in the near future. It's also good to see that g++-7.1 also did make the build faster than gcc-6.3. However, the fastest gcc version for optimization is still gcc-4.9.4 which is already an old branch with low C++ standard support.
Runtime Performance
Let's now take a look at the quality of the generated code. For some of the benchmarks, I've included two versions of the algorithm. std is the most simple algorithm (the naive one) and vec is the hand-crafted vectorized and optimized implementation. All the tests were done on single-precision floating points.
Dot Product
The first benchmark that is run is to compute the dot product between two vectors. Let's look first at the naive version:

The differences are not very significant between the different compilers. The clang-based compilers seem to be the compilers producing the fastest code. Interestingly, there seem to have been a big regression in gcc-6.3 for large containers, but that has been fixed in gcc-7.1.

If we look at the optimized version, the differences are even slower. Again, the clang-based compilers are producing the fastest executables, but are closely followed by gcc, except for gcc-6.3 in which we can still see the same regression as before.
Logistic Sigmoid
The next test is to check the performance of the sigmoid operation. In that case, the evaluator of the library will try to use parallelization and vectorization to compute it. Let's see how the different compilers fare:
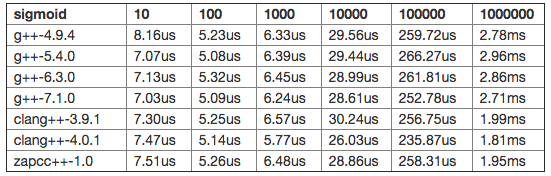
Interestingly, we can see that gcc-7.1 is the fastest for small vectors while clang-4.0 is the best for producing code for larger vectors. However, except for the biggest vector size, the difference is not really significantly. Apparently, there is a regression in zapcc (or clang-5.0) since it's slower than clang-4.0 at the same level as clang-3.9.
Y = Alpha * X + Y (axpy)
The third benchmark is the well-known axpy (y = alpha * x + y). This is entirely resolved by expressions templates in the library, no specific algorithm is used. Let's see the results:
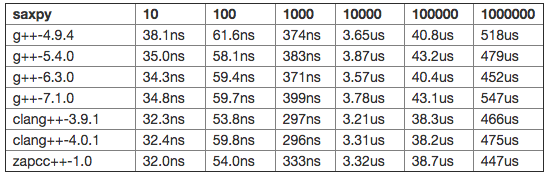
Even on the biggest vector, this is a very fast operation, once vectorized and parallelized. At this speed, some of the differences observed may not be highly significant. Again clang-based versions are the fastest versions on this code, but by a small margin. There also seems to be a slight regression in gcc-7.1, but again quite small.
Matrix Matrix Multiplication (GEMM)
The next benchmark is testing the performance of a Matrix-Matrix Multiplication, an operation known as GEMM in the BLAS nomenclature. In that case, we test both the naive and the optimized vectorized implementation. To save some horizontal space, I've split the tables in two.
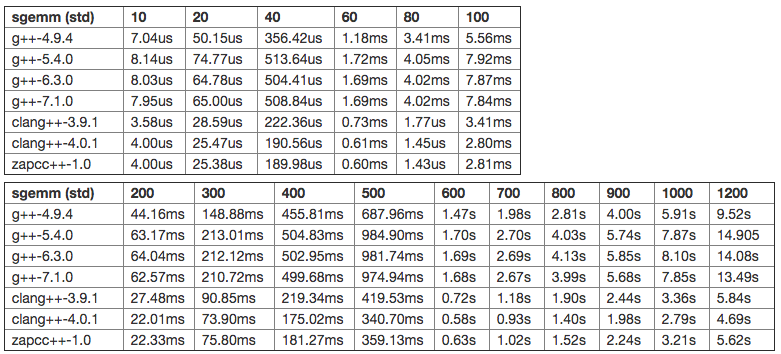
This time, the differences between the different compilers are very significant. The clang compilers are leading the way by a large margin here, with clang-4.0 being the fastest of them (by another nice margin). Indeed, clang-4.0.1 is producing code that is, on average, about twice faster than the code generated by the best GCC compiler. Very interestingly as well, we can see a huge regression starting from GCC-5.4 and that is still here in GCC-7.1. Indeed, the best GCC version, in the tested versions, is again GCC-4.9.4. Clang is really doing an excellent job of compiling the GEMM code.
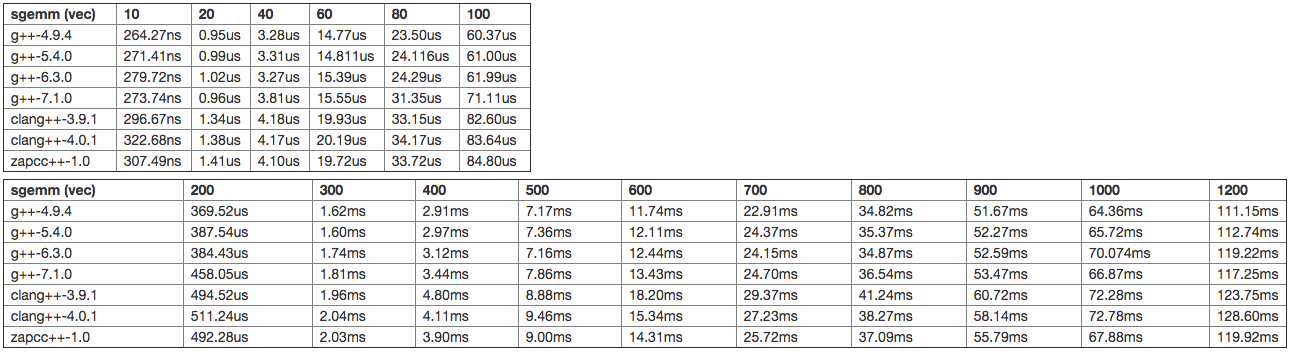
As for the optimized version, it seems that the two families are reversed. Indeed, GCC is doing a better job than clang here, and although the margin is not as big as before, it's still significant. We can still observe a small regression in GCC versions because the 4.9 version is again the fastest. As for clang versions, it seems that clang-5.0 (used in zapcc) has had some performance improvements for this case.
For this case of matrix-matrix multiplication, it's very impressive that the differences in the non-optimized code are so significant. And it's also impressive that each family of compilers has its own strength, clang being seemingly much better at handling unoptimized code while GCC is better at handling vectorized code.
Convolution (2D)
The last benchmark that I considered is the case of the valid convolution on 2D images. The code is quite similar to the GEMM code but more complicated to optimized due to cache locality.

In that case, we can observe the same as for the GEMM. The clang-based versions are much producing significantly faster code than the GCC versions. Moreover, we can also observe the same large regression starting from GCC-5.4.

This time, clang manages to produce excellent results. Indeed, all the produced executables are significantly faster than the versions produced by GCC, except for GCC-7.1 which is producing similar results. The other versions of GCC are falling behind it seems. It seems that it was only for the GEMM that clang was having a lot of troubles handling the optimized code.
Conclusion
Clang seems to have recently done a lot of optimizations regarding compilation time. Indeed, clang-4.0.1 is much faster for compilation than clang-3.9. Although GCC-7.1 is faster than GCC-6.3, all the GCC versions are slower than GCC-4.9.4 which is the fastest at compiling code with optimizations. GCC-7.1 is the fastest GCC version for compiling code in debug mode.
In some cases, there is almost no difference between different compilers in the generated code. However, in more complex algorithms such as the matrix-matrix multiplication or the two-dimensional convolution, the differences can be quite significant. In my tests, Clang has shown to be much better at compiling unoptimized code. However, and especially in the GEMM case, it seems to be worse than GCC at handling hand-optimized. I will investigate that case and try to tailor the code so that clang is having a better time with it.
For me, it's really weird that the GCC regression, apparently starting from GCC-5.4, has still not been fixed in GCC 7.1. I was thinking of dropping support for GCC-4.9 in order to go full C++14 support, but now I may have to reconsider my position. However, seeing that GCC is generally the best at handling optimized code (especially for GEMM), I may be able to do the transition, since the optimized code will be used in most cases.
As for zapcc, although it is still the fastest compiler in debug mode, with the new speed of clang-4.0.1, its margin is quite small. Moreover, on optimized build, it's not as fast as GCC. If you use clang and can have access to zapcc, it's still quite a good option to save some time.
Overall, I have been quite pleased by clang-4.0.1 and GCC-7.1, the most recent versions I have been testing. It seems that they did quite some good work. I will definitely run some more tests with them and try to adapt the code. I'm still considering whether I will drop support for some older compilers.
Published at DZone with permission of Baptiste Wicht, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.